
Apa itu deep learning dan bagaimana cara kerja nya?. Artikel ini ditulis untuk siapapun yang ingin mengetahui apa itu Deep Learning dan Neural Network. Tulisan ini akan membahas mengenai arti dari Deep Learning dan Neural Network.
Konsep yang akan dibahas secara khusus pada artikel ini adalah bagaimana cara kerja Deep Learning secara praktis.
Apakah Anda pernah bertanya-tanya mengenai aplikasi pendeteksi wajah untuk membuka password smartphone Anda? Atau ketika Anda mencari sesuatu pada mesin pencari google, lalu ketika membuka facebook, maka akan muncul iklan yang sesuai dengan apa yang Anda cari? Atau ketika Anda membuka youtube, banyak sekali video rekomendasi yang muncul sesuai dengan selera Anda?
Selain itu, yang lebih mutakhir adalah dengan adanya mobil yang bisa berjalan sendiri seperti yang di iklankan oleh Elon Musk.
Semua itu adalah produk dari Deep Learning dan Neural Networks. Sebelum kita memulai, alangkah baiknya kita membahas definisi dan konsep dari Deep Learning terlebih dahulu.
Apa itu Deep Learning?
Deep Learning adalah bagian dari Machine Learning yang juga merupakan bagian dari Artificial Intelligence (kecerdasan buatan). Artificial Intelligence (AI) adalah istilah umum yang mengacu pada teknik dimana komputer memungkinkan untuk meniru perilaku manusia.
Sedangkan Machine Learning merepresentasikan sekumpulan algoritma yang telah dilatih berdasarkan data yang ada.
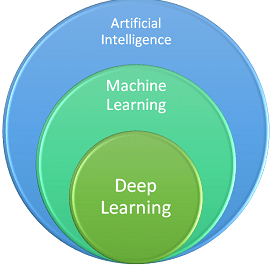
Deep learning adalah salah satu tipe dari algoritma Machine Learning yang terinspirasi oleh struktur otak pada manusia. Algoritma pada deep learning mencoba untuk mengambil suatu kesimpulan sebagaimana halnya pada manusia dalam menganalisa data berdasarkan struktur logika yang diberikan secara berkelanjutan. Untuk mencapai tujuan tersebut, deep learning menggunakan struktur algoritma multilayer yang disebut neural networks.
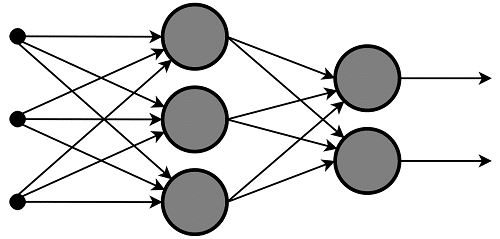
Desain dari neural network ini didasarkan pada struktur otak manusia. Sama halnya seperti manusia dalam menggunakan otaknya untuk mengidentifikasi pola dan mengklasifikasikan berbagai jenis informasi. Neural network ini pun dapat kita latih untuk melakukan tugas yang sama berdasarkan data yang digunakan.
Layer individual pada neural networks dapat juga dianalogikan sebagai filter yang bekerja untuk menyaring sesuatu dari kasar kepada yang lembut, sehingga akan meningkatkan kemungkinan untuk melakukan pendeteksian dengan benar, begitupun output nya.
Otak manusia pun bekerja seperti itu, setiap kali kita menerima informasi yang baru, otak akan mencoba membandingkan dengan objek yang telah diketahui sebelumnya. Konsep ini lalu diaplikasikan oleh deep neural networks.
Neural network memungkinkan kita untuk melakukan banyak tugas, seperti pengklasteran (clustering), klasifikasi (classification) ataupun regresi (regression). Dengan algoritma neural networks, kita dapat mengelompokkan atau menyortir data yang belum memiliki label berdasarkan kesamaannya terhadap sampel lain di dalam suatu dataset. Atau pada kasus pengklasifikasian, kita dapat melatih (train) jaringan (network) tersebut pada dataset yang telah memiliki label. Hal ini dilakukan untuk mengklasifikasikan sampel pada suatu dataset kepada kategori yang berbeda
Artificial neural network, memiliki kemampuan unik. Model deep learning ini dapat menyelesaikan masalah yang tidak dapat diselesaikan oleh model machine learning yang lain.
Seluruh kemajuan terbaru dalam bidang kecerdasan buatan dalam beberapa tahun terakhir ini disebabkan oleh adanya Deep Learning. Tanpa adanya algoritma deep learning, kita tidak akan dapat menemui kendaraan tanpa awak, chatbot ataupun personal assistant seperti Alexa. Netflix atau Youtube tidak akan mengetahui video atau film apa yang kita sukai atau tidak disukai. Di belakang teknologi mutakhir tersebut tidak akan tercapai tanpa adanya neural network.
Pada akhirnya, deep learning adalah pendekatan terbaik untuk algoritma kecerdasan buatan yang ada hingga saat ini.
Mengapa Deep Learning begitu populer saat ini?
Apa yang menyebabkan deep learning dan neural network begitu kuat di industri pada saat ini? Mengapa model deep learning lebih handal dibandingkan dengan machine learning?
Keuntungan utama dari deep learning dibandingkan dengan machine learning adalah tidak diperlukannya proses ekstraksi fitur (feature extraction). Jauh sebelum deep learning digunakan, metode machine learning seperti Decision Tree, SVM, Naive Bayes Classifier dan Logistic Regression telah digunakan.
Algoritma yang disebutkan sebelumnya merupakan algoritma datar. Datar di sini berarti bahwa algoritma ini tidak dapat diterapkan secara langsung pada data mentah (seperti .csv, gambar, teks, dll). Melainkan, kita membutuhkan langkah preprocessing terlebih dahulu yang disebut dengan ekstraksi fitur.
Hasil fitur ekstraksi ini adalah representasi data mentah yang baru dapat digunakan oleh algoritma machine learning untuk melakukan sesuatu. Sebagai contoh, pengklasifikasian data terhadap beberapa kategori atau kelas.
Ekstraksi fitur ini cukup kompleks dan membutuhkan pengetahuan domain yang mendetail. Layer pre-processing ini perlu diadaptasi, di uji dan disempurnakan melalui beberapa iterasi untuk mendapatkan hasil yang optimal.
Artificial Neural Network pada Deep Learning. Tidak memerlukan langkah ekstraksi fitur.
Layer pada neural network dapat belajar secara implisit dari raw data secara langsung. Data mentah yang semakin abstrak dan terkompresi dihasilkan melalui beberapa lapisan artificial neural network. Representasi data terkompresi dari input data ini digunakan untuk menghasilkan output. Hasilnya dapat berupa klasifikasi dari data input ke dalam kelas yang berbeda.
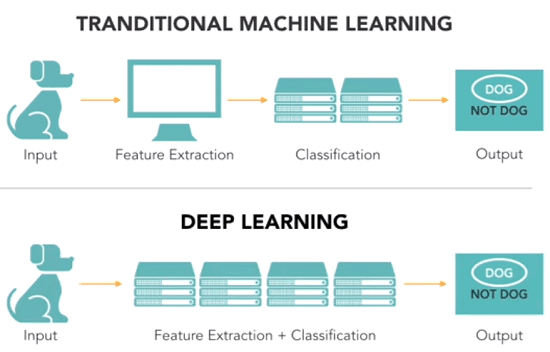
Dengan kata lain, kita pun dapat menyebutkan bahwa langkah ekstraksi fitur sudah merupakan bagian dari proses di dalam artificial neural network.
Selama proses training, langkah ini pun di optimasi oleh neural network untuk mendapatkan representasi abstrak terbaik dari input data. Artinya, model deep learning hanya memerlukan sedikit atau tanpa upaya manual untuk melakukan dan mengoptimalkan proses ekstraksi fitur
Sebagai contoh, Jika Anda ingin menggunakan model machine learning untuk menentukan gambar tertentu untuk menunjukan seekor anjing atau bukan, kita sebagai manusia perlu mengidentifikasikan fitur yang unik dari hewan tersebut (bentuk kepala, telinga, mata, dll). Lalu, kita mengekstrak fitur tersebut dan memberikannya kepada algoritma sebagai input data.
Dengan cara demikian, algoritma akan melakukan pengklasifikasian pada gambar. Artinya, dalam machine learning, seorang developer perlu campur tangan secara langsung agar model yang dikembangkan mencapai suatu kesimpulan yang tepat.
Dalam hal model pada deep learning, tahap ekstraksi fitur benar-benar tidak dibutuhkan. Model algoritmanya akan mengenali karakteristik yang unik dari seekor anjing, lalu membuat prediksi yang tepat tanpa bantuan manusia. Kita hanya perlu memberikan data mentah, lalu sisanya dikerjakan oleh model tersebut.
Era Big Data
Keuntungan besar yang kedua dari deep learning yang membuat nya begitu populer adalah dengan jumlah data yang sangat banyak. Era teknologi big data akan memberikan jumlah kesempatan yang sangat besar untuk berinovasi pada deep learning. Seperti yang telah dikatakan oleh Andrew Ng, Chief Scientist Baidu dan salah satu leader Google Brain Project,
“Analogi terhadap apa itu deep learning adalah bahwa model deep learning adalah suatu mesin roket dan bahan bakarnya adalah jumlah data yang melimpah di mana kita dapat memberikannya pada algoritma tersebut”
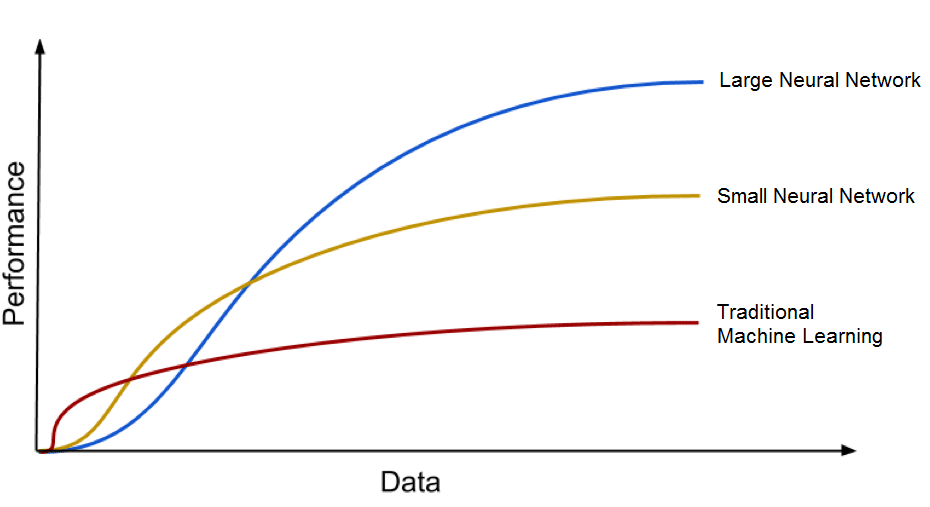
Model deep learning memiliki trend meningkatkan akurasi dengan bertambahnya jumlah data yang di training. Sedangkan tradisional machine learning seperti pengklasifikasian SVM dan Naive Bayes berhenti meningkat setelah menemui titik jenuh.
Jaringan syaraf (Neural Networks) Biologis
Sebelum kita berjalan lebih jauh dengan artificial neural networks dan memahami lebih dalam apa itu deep learning, mari kita bahas terlebih dahulu mengenai konsep neural network biologis. Sehingga, ketika membahas mengenai artificial neural network secara lebih detail, kita dapat melihat secara paralel dengan model jaringan saraf biologis.
Artificial neural network terinspirasi oleh neuron pada jaringan saraf manusia yang dapat ditemukan di dalam otak. Faktanya, artificial neural network mensimulasikan beberapa fungsi dasar dari jaringan saraf pada otak kita, namun, dengan cara yang sangat sederhana.
Pertama-tama, mari kita perhatikan jaringan saraf biologis dan melihatnya secara paralel dengan artificial neural networks.
![Jaringan saraf biologis. [Apa itu neural network]](https://auftechnique.com/wp-content/uploads/2021/06/biological-neural-network.png)
Jaringan saraf biologis terdiri dari banyak neuron. Neuron sendiri memiliki badan sel, dendrit dan akson. Dendrit merupakan struktur tipis yang muncul dari badan sel. Akson adalah ekstensi selular yang muncul dari badan sel ini. Sebagian besar neuron menerima sinyal melalui dendrit, lalu mengirimkannya di sepanjang akson.
Pada sebagian besar sinapsis, sinyal melintas dari akson suatu neuron ke dendrit pada neuron lainnya. Seluruh neuron tereksitasi secara elektrik karena voltase gradien dari membrannya. Jika ada perubahan voltase cukup besar pada interval yang singkat, neuron akan menghasilkan pulsa electrochemical yang disebut aksi potensial. Potensial ini bergerak cepat di sepanjang akson dan mengaktifkan koneksi sinaptik saat mencapainya.
Jaringan syaraf buatan (Artificial Neural Networks)
Setelah kita membahas pemahaman dasar mengenai jaringan saraf biologis pada bagian sebelumnya, sekarang mari kita lihat arsitektur jaringan syaraf tiruan dan apa itu deep learning.
Neural network, secara umum terdiri dari kumpulan unit atau node yang saling terhubung. Kita dapat menyebutnya sebagai node neuron. Neuron tiruan ini secara tidak langsung merupakan model dari neuron biologis pada otak kita.
[Apa itu deep learning].Neuron hanyalah representasi grafis dari nilai numerik (misalkan 1.7, 4.0, 33.0, 0.5, dll). Hubungan antara dua neuron tiruan dapat dianggap sebagai akson dalam otak biologis. Hubungan antara neuron diwujudkan dengan sesuatu yang disebut bobot (weight). Di mana bobot ini tidak lebih dari suatu nilai numerik.
Ketika artificial neural network belajar, bobot (weight) di antara neuron akan berubah begitupun kekuatan koneksinya. Artinya, dari data training yang diberikan dan tugas tertentu seperti mengklasifikasikan nomor, kita mencari set bobot tertentu yang memungkinkan neural network berfungsi sebagai klasifikasi. Kumpulan bobot ini berbeda untuk setiap tugas dan kumpulan datanya. Kita tidak dapat memprediksikan bobot ini sebelumnya. Namun, neural network harus mempelajarinya. Proses pembelajaran disebut juga dengan training
Arsitektur Neural Network
Arsitektur neural network, terdiri dari beberapa lapisan. Lapisan pertama kita dapat menyebutnya input layer.
Input layer menerima input x, yang merupakan data dimana neural network belajar. Pada contoh sebelumnya dari pengklasifikasian tulisan tangan, input berupa x, merepresentasikan gambar dari nomor tersebut (x pada dasarnya adalah seluruh vektor di mana setiap entrinya berupa pixel).
Input layer memiliki jumlah neuron yang sama dengan jumlah entri pada vektor x. Artinya, setiap input neuron mewakili satu elemen di dalam vektor x.
Lapisan terakhir disebut juga output layer,memiliki output vektor y, yang mewakili hasil output dari neural network. Entri dalam vektor ini mewakili nilai neuron di output layer. Pada kasus klasifikasi ini, setiap neuron pada lapisan terakhir akan mewakili kelas yang berbeda.
Dalam hal ini, nilai output neuron memberikan probabilitas bahwa digit tulisan tangan yang diberikan oleh fitur x kemungkinan termasuk ke dalam salah satu kelas ( salah satu dari digit 0-9). Seperti yang kita bayangkan, jumlah output neuron harus sama dengan kelas yang ada.
Untuk mendapatkan vektor hasil prediksi y, neural network harus melakukan operasi matematika tertentu. Operasi ini dilakukan pada lapisan antara input dan output. Kita dapat menyebutnya hidden layer. Pada bagian selanjutnya pada artikel apa itu deep learning akan membahas mengenai koneksi antar layer.
Koneksi antar layer pada Neural Network
Sebagai contoh, jika neural network hanya memiliki dua layer. Di mana input layer memiliki dua input neuron, lalu output nya memiliki tiga neuron seperti pada ilustrasi di bawah ini:

Weight antar neuron. [Apa itu deep learning]
Seperti yang telah dibahas sebelumnya dalam pembahasan apa itu deep learning. Setiap koneksi antar neuron direpresentasikan oleh nilai numerik yang kita sebut bobot (weight) w. Setiap w ini memiliki indeks. Angka pertama pada index menunjukkan nomor neuron dari layer asalnya, angka kedua adalah nomor neuron sambungan layer yang dituju.
Seluruh weight antara dua neural network dapat direpresentasikan dalam bentuk matriks seperti pada persamaan di bawah ini:

Matriks Weight (bobot). [Apa itu deep learning]
Matriks weight ini memiliki jumlah entri yang sama seperti koneksi yang di antara neuron. Dimensi bobot matriks ini dihasilkan dari ukuran dua layer yang terkoneksi berdasarkan bobot matriks tersebut.
Jumlah baris akan sesuai dengan jumlah neuron dari layar, dimana koneksi itu berasal dan jumlah kolomnya sesuai dengan jumlah layer dari tujuan koneksi tersebut.
Pada contoh kasus ini, jumlah baris dari bobot matriks ini adalah dua (ukuran layer input) dan jumlah ukuran kolomnya adalah tiga (ukuran layer output).
Proses training pada Neural Network
Setelah memahami arsitektur neural network dengan baik, sekarang saat nya untuk proses “belajar” pada jaringan saraf tiruan ini. Di harapkan Anda akan lebih mengerti apa itu deep learning.
Misalkan dengan fitur input vektor x, neural network menghitung prediksi vektor yang dapat kita sebut h.
Step ini dalam pembahasan apa itu deep learning disebut juga sebagai forward propagation. Dengan input vektor x dan bobot matriks W yang mengkoneksikan antara dua layer, kita dapat menghitung hasil produk dari vektor x dan matrik W.
Hasil dari produk ini pun berupa vektor yang dapat kita sebut z.

Vektor produk z. [Apa itu deep learning]
Nilai vektor prediksi akhir h didapatkan dengan cara mengaplikasikan fungsi aktivasi (activation function) terhadap vektor z. Dalam hal ini, fungsi aktivasi ini diwakili dengan simbol huruf Sigma. Fungsi aktifasi ini hanya suatu fungsi non linear yang dapat melakukan pemetaan nonlinear dari z ke h.
Ada 3 fungsi aktivasi yang digunakan dalam deep learning, yaitu tanh, sigmoid dan ReLu.
Sekarang mungkin Anda akan mengenali makna di balik neuron dalam jaringan saraf tiruan. Neuron hanyalah representasi dari nilai numerik. Nilai ini memberikan informasi seberapa kuat neuron ini terhubung satu sama lainnya.
Selama proses training, bobot ini disesuaikan, beberapa neuron akan menjadi lebih erat terhubung, dan beberapa jadi kurang terhubung. Seperti halnya pada jaringan saraf biologis, pembelajaran berarti adanya perubahan bobot. Dengan demikian, nilai z, h dan vektor output akhir y, berubah seiring dengan perubahan bobot. Beberapa bobot membuat prediksi neural network mendekati nilai yang benar sesuai dasarnya y_hat, beberapa bobot meningkatkan jarak dari nilai dasar vektor tersebut.
Kita dapat meningkatkan pengetahuan kita dengan arsitektur lebih dalam yang memiliki 5 layer.

Arsitektur 5 layer neural network. [Apa itu deep learning]
Sama seperti sebelumnya, hasil antara input x dan bobot pertama matriks W1 dan mengimplementasikan fungsi aktivasi terhadap hasil vektor untuk mendapatkan hidden layer vektor h1. h1 ini sekarang bisa dikatakan sebagai input dari layer ketiga. Seluruh prosedur dari sebelumnya di ulang-ulang hingga mendapatkan output akhir y.

Hasil output y. [Apa itu deep learning]
Loss Function
Setelah mendapatkan hasil prediksi dari neural network, langkah selanjutnya adalah membandingkan vektor prediksi dengan label dasar sebenarnya. Kita dapat menyebutnya sebagai vektor y_hat.
Vektor y berisi prediksi yang telah dihitung neural network selama proses forward propagation (bisa jadi pada kenyataannya, nilai akan berbeda dari sebenarnya), sedangkan vektor y_hat berisi nilai sebenarnya.
Secara matematis, kita dapat mengukur perbedaan nilai antara y dan y_hat dengan cara menggunakan loss function, dimana nilainya tergantung pada selisihnya.
Contoh loss function secara umum adalah quadratic loss:
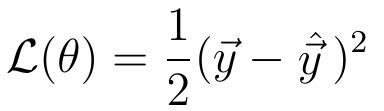
Quadratic loss function. [Apa itu deep learning]
Nilai dari loss function ini tergantung pada perbedaan antara y_hat dan y. Semakin besar perbedaannya, artinya memiliki nilai loss yang lebih tinggi. Sebaliknya, semakin kecil perbedaannya, maka nilai loss akan mengecil.
Meminimalkan loss function, akan menjadikan hasil prediksi neural network lebih akurat, karena perbedaan prediksi dan label menjadi berkurang. Secara otomatis menyebabkan model neural network membuat prediksi lebih baik terlepas dari karakteristik tugas sebenarnya. Anda hanya perlu memilih loss function yang tepat untuk tugas tertentu. Untungnya, hanya ada dua loss function yang harus Anda ketahui untuk menyelesaikan hampir seluruh masalah yang dihadapi dalam prakteknya.
Loss function ini adalah Cross-Entropy Loss:
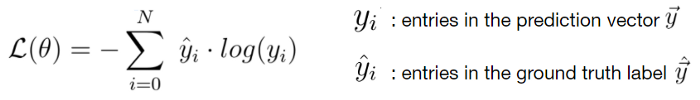
Dan yang kedua adalah Mean Squared Error Loss:

Oleh karena loss bergantung pada bobot, kita perlu menemukan kumpulan bobot tertentu yang memiliki loss function sekecil mungkin. Metode untuk meminimalkan loss function tersebut secara matematis dapat menggunakan metode yang disebut penurunan gradien ( gradient descent)
Gradient Descent (Penurunan Gradien)
Selama penurunan gradien, kita dapat menggunakan fungsi loss gradien untuk meningkatkan bobot neural network.
Untuk memahami konsep dasar dari proses penurunan gradien, mari kita ambil contoh dasar dari jaringan saraf yang hanya terdiri dari satu neuron input dan satu output yang dihubungkan dengan nilai bobot w.
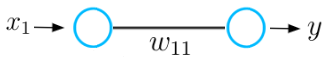
Jaringan saraf ini menerima input x dan mengeluarkan prediksi y. Misalkan nilai bobot awal neural network ini adalah 5 dan input x adalah 2. Oleh karena itu prediksi y jaringan ini memiliki nilai 10, sedangkan label y_hat mungkin memiliki nilai 6.

Ini berarti prediksi tersebut tidak akurat dan kita harus menggunakan metode gradient descent untuk menemukan nilai bobot baru yang membuat prediksi neural network menjadi benar. Pada langkah pertama, kita perlu memiliki loss function. Mari kita ambil quadratic loss yang telah kita tentukan sebelumnya dan plot dari fungsi tersebut. Sederhananya, fungsi kuadratik itu seperti:

Fungsi kuadratis sederhana. [Apa itu deep learning]
Sumbu y adalah nilai dari loss yang bergantung pada perbedaan antara label dan prediksi.
Dalam hal ini parameter jaringan memiliki satu weight w. Sedangkan sumbu x adalah nilai dari bobot tersebut. Seperti yang dapat Anda perhatikan, ada nilai bobot tertentu w yang fungsi loss nya mencapai minimum secara global. Nilai ini adalah parameter bobot paling optimal yang membuat prediksi neural network menjadi benar, yaitu 6. Dalam hal ini, nilai bobot optimalnya adalah 3:

Bobot awal secara grafis. [Apa itu deep learning]
Di sisi lain, nilai awal bobot kita adalah 5, yang mengarah pada bobot loss yang cukup tinggi. Target dari proses ini adalah untuk memperbarui parameter bobot berulang kali sehingga mencapai nilai yang optimal untuk bobot tertentu tersebut. Pada kondisi ini kita perlu menggunakan gradien dari loss function. Kabar baiknya, loss function adalah fungsi dari satu variabel tunggal, yaitu bobot w:
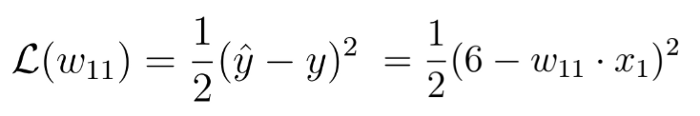
Fungsi loss function terhadap bobot w. [Apa itu deep learning]
Pada tahap selanjutnya, kita akan menghitung turunan dari loss function dengan parameter ini:

Turunan fungsi loss function terhadap bobot w. [Apa itu deep learning]
Pada akhirnya, kita akan mendapatkan hasil 8, dimana memberikan kita nilai dari slope (kemiringan) atau tangent dari loss function untuk titik yang sesuai pada sumbu x di mana bobot awal berada.
Garis singgung ini mengarah ke tingkat tertinggi dari peningkatan loss function dan parameter bobot yang sesuai pada sumbu x.
Ini artinya kita telah menggunakan gradien dari loss function untuk menemukan parameter bobot mana yang memiliki nilai loss lebih tinggi. Namun, yang ingin kita ketahui adalah kebalikannya. Kita akan mendapatkan apa yang kita inginkan jika mengalikannya dengan minus 1. Dengan cara demikian, kita akan mendapatkan arah kebalikan dari gradien tersebut. Cara ini akan memberikan kita arah tingkat penurunan tertinggi dari loss function dan parameter yang membuat penurunan pada sumbu x:

Penurunan gradient. [Apa itu deep learning]
Pada langkah terakhir, kita melakukan satu step penurunan gradien sebagai upaya untuk meningkatkan bobot w. Kita menggunakan gradien negatif ini untuk memperbarui bobot saat ini ke arah bobot yang nilai loss functionnya berkurang sesuai dengan gradien negative:


Perhitungan bobot baru dengan penurunan gradient. [Apa itu deep learning]
Faktor epsilon pada persamaan ini adalah hyperparameter yang disebut dengan learning rate. Learning rate ini menentukan seberapa cepat atau lambat Anda ingin memperbarui suatu parameter. Harap diingat bahwa learning rate adalah faktor yang harus kita gunakan untuk mengalikan gradien negatif. Nilai learning rate ini biasanya cukup kecil, dalam hal ini adalah 0.1.
Seperti yang telah Anda lihat, bobot w setelah penurunan gradien, kini menjadi 4.2, dan lebih dekat ke bobot optimal daripada sebelum step gradien.

Bobot awal dan akhir. [Apa itu deep learning]
Nilai dari loss function untuk bobot yang baru pun lebih kecil, artinya neural network sudah memiliki kemampuan yang lebih baik untuk memprediksi. Anda dapat melakukan kalkulasi di dalam pikiran Anda dan melihat hasil prediksi terbaru akan lebih mendekati kepada label dibandingkan sebelumnya.
Setiap kali kita melakukan update pada bobot, kita bergerak menuju gradien negatif ke arah bobot optimal.
Setelah setiap penurunan langkah gradien atau update bobot, bobot terbaru pada jaringan menjadi lebih dekat dan dekat terhadap bobot optimal dan akan mencapainya. Sehingga neural network akan mampu memprediksikan sesuai dengan apa yang kita inginkan.
Kesimpulan
Anda telah memahami konsep dasar apa itu deep learning dan bagaimana cara kerjanya dengan penjabaran yang sangat sederhana. Anda akan terbiasa dan lebih mengerti mengenai algoritma ini dengan secara langsung praktek cara penggunaannya. Salah satu contohnya adalah untuk aplikasi object detection dengan menggunakan framework terpopuler Tensorflow.
Sumber:
Adaptasi dari: https://towardsdatascience.com/what-is-deep-learning-and-how-does-it-work-2ce44bb692ac
Machine Learning Mastery



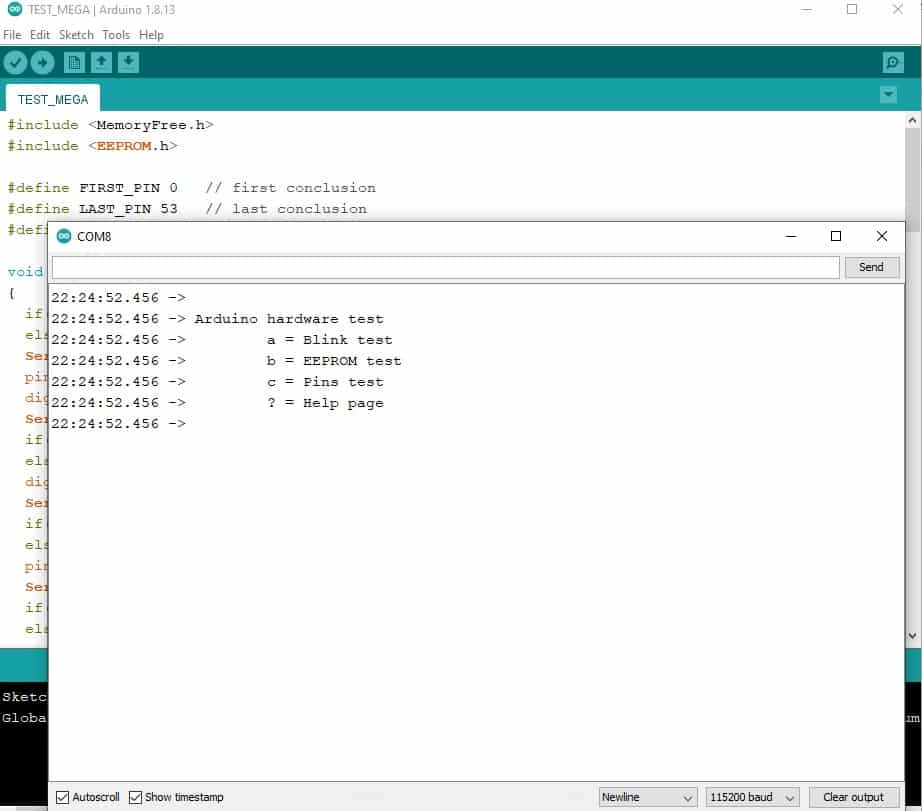
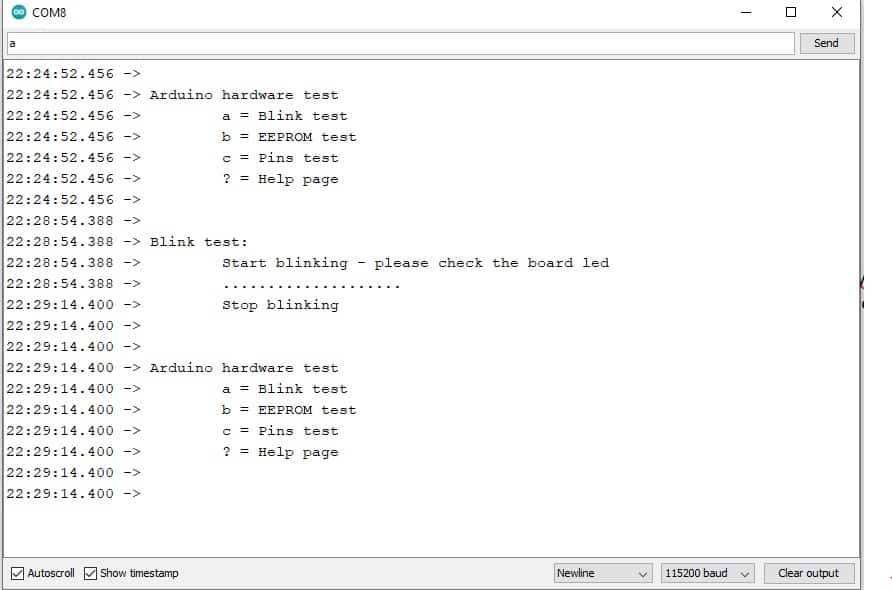
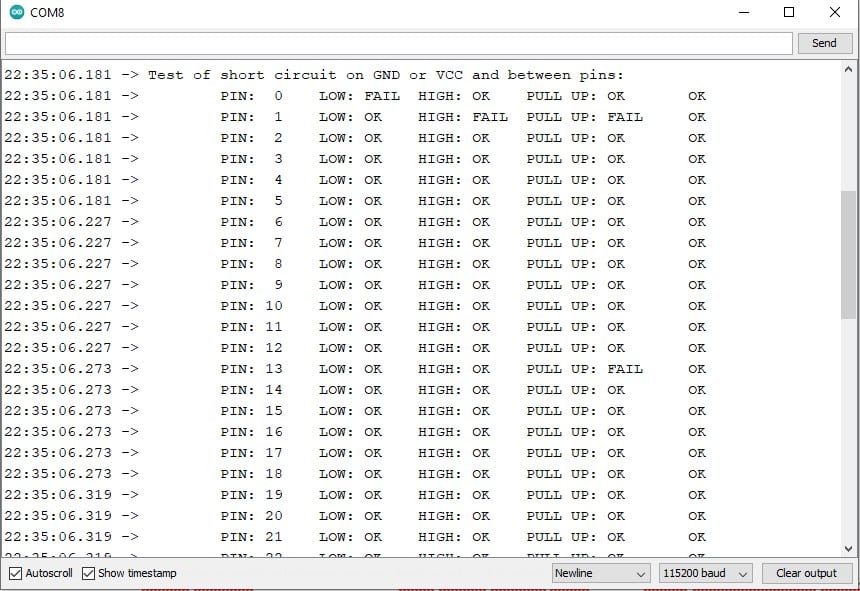
![[Menggunakan Arduino Robotdyn Mega WiFi]. Tabel DIP Switch](https://auftechnique.com/wp-content/uploads/2020/12/Tabel-lengkap-robotdyn-mega-wifi.jpg)
![[Menggunakan Arduino Robotdyn Mega WiFi]. Update Serial Driver](https://auftechnique.com/wp-content/uploads/2020/12/Update-Serial-Driver.png)
![[Menggunakan Arduino Robotdyn Mega WiFi]. Lokasi COM Port](https://auftechnique.com/wp-content/uploads/2020/12/Lokasi-COM-Port.png)

![[Menggunakan Arduino Robotdyn Mega WiFi]. Pilih Board Mega 2560](https://auftechnique.com/wp-content/uploads/2020/12/Pilih-board-Mega-2560.jpg)


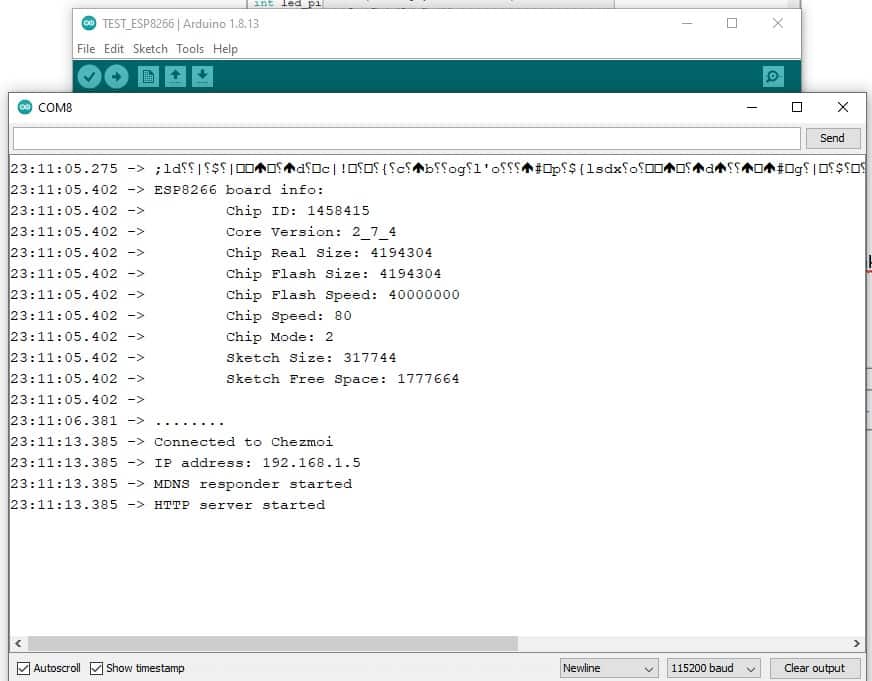

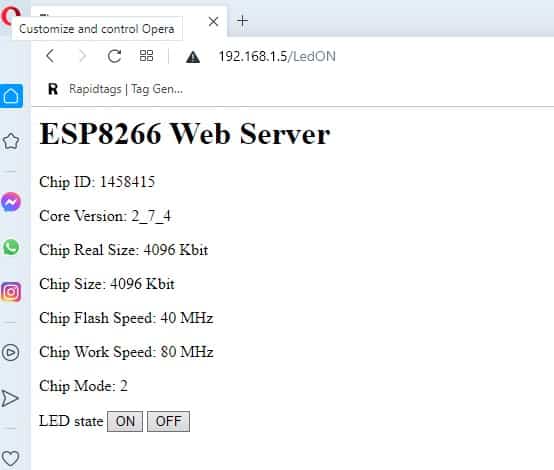
![[Apa itu Nodemcu]. ESP 12 E Modul](https://auftechnique.com/wp-content/uploads/2020/12/ESP-12-E-Module.jpg)
![[Apa itu Nodemcu]. Power Nodemcu](https://auftechnique.com/wp-content/uploads/2020/12/Power-Nodemcu.jpg)
![[Apa itu Nodemcu]. Peripheral dan IO NodeMCU](https://auftechnique.com/wp-content/uploads/2020/12/Peripherals-dan-IO-Nodemcu.jpg)
![[Apa itu Nodemcu]. Tombol dan indikator Nodemcu](https://auftechnique.com/wp-content/uploads/2020/12/Tombol-dan-indikator-Nodemcu.jpg)
![[Apa itu Nodemcu].Komunikasi Serial Nodemcu](https://auftechnique.com/wp-content/uploads/2020/12/Komunikasi-Serial-Nodemcu.jpg)
![[Apa itu Nodemcu].NodeMCU pin](https://auftechnique.com/wp-content/uploads/2020/12/NodeMCU-pin.png)
![[Rekomendasi Laptop untuk Programming Machine Learning]. Asus ROG Strix SCAR G732LXS](https://auftechnique.com/wp-content/uploads/2020/11/Asus-ROG-Strix-SCAR-G732LXS.jpg)
![[Rekomendasi Laptop untuk Programming Machine Learning]. Acer Predator Helios PH717](https://auftechnique.com/wp-content/uploads/2020/11/Acer-Predator-Helios-PH717.jpg)


![[Contoh aplikasi Python] Google](https://auftechnique.com/wp-content/uploads/2020/11/aplikasi-python-pada-google.png)
![[Contoh aplikasi Python] Grab dan Gojek](https://auftechnique.com/wp-content/uploads/2020/11/contoh-aplikasi-python-pada-gojek-dan-grab.jpg)

![[Belajar Machine Learning] Ilustrasi Persiapan Data](https://auftechnique.com/wp-content/uploads/2020/11/menyiapkan-data.jpg)
![[Belajar Machine Learning] Ilustrasi Mengecek Algoritma](https://auftechnique.com/wp-content/uploads/2020/11/menyiapkan-algoritma.jpg)
![[Belajar Machine Learning] Pendeteksi Objek](https://auftechnique.com/wp-content/uploads/2020/11/pendeteksi-objek.png)

![[Sejarah Python] Pro dan Kontra Python](https://auftechnique.com/wp-content/uploads/2020/11/pro-dan-kontra.jpg)
![[Sejarah Python] Ilustrasi operating system](https://auftechnique.com/wp-content/uploads/2020/11/operating-system.png)


